可灵AI 3.0发布,让AI‘认人’了。一段3秒视频,就能生成主角一致的成片。
最新AI落地实操,点击了解:https://qimuai.cn/
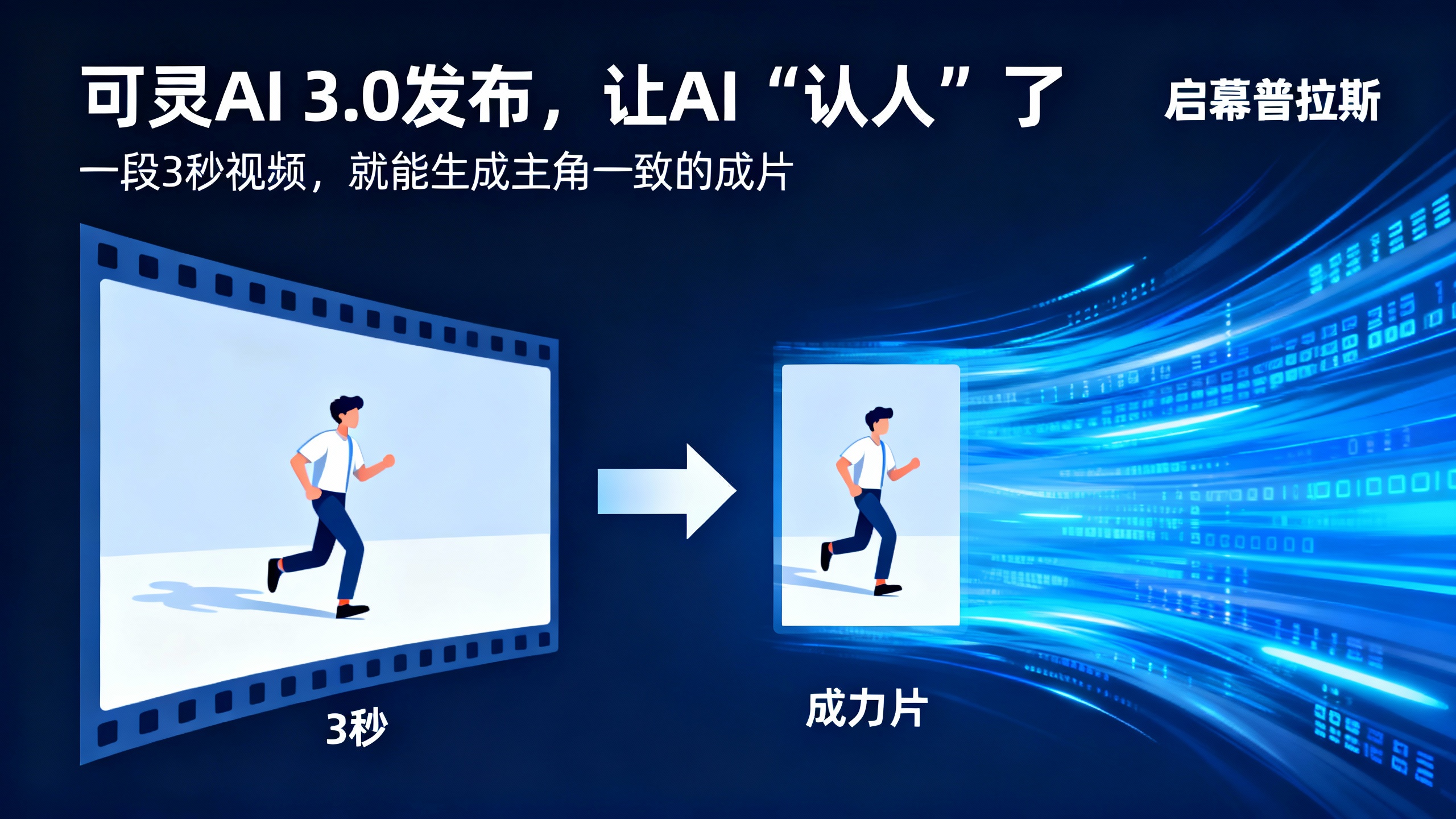
终于,能让人物在视频里“认”出来了。
今天凌晨,国内顶级的视频生成团队扔下了一颗重磅炸弹。可灵AI的3.0系列模型,正式来了。
这可不是简单的画质升级。过去一年,我们见证了AI从生成静态图片,到做出几秒闪动的动画。但想用它讲一个连贯的故事?难。主角换个角度就“变脸”,道具凭空消失,口型对不上配音……这些小毛病,足以让任何精心构思的剧情瞬间出戏。
但今天之后,游戏规则可能要彻底改写。
可灵AI 3.0,尤其是其中的视频3.0 Omni版本,干了一件很“疯”的事:它让AI真正学会了“认人”。
你只需给AI一段3-8秒的主角视频,它就能提取出这个人独一无二的形象、动作特征,甚至音色。接下来,无论你是在生成全新的复杂镜头,还是让他/她做出不同的表情动作,这个“主角”都能保持惊人的一致。
头发、衣着、面部特征,稳如磐石。这,就是他们全球首创的 “图生视频+主体参考” 能力。
这意味着什么?意味着你终于可以构思一个完整的短片脚本,然后让AI担任执行导演,确保主角从头到尾都是同一个人。品牌想用同一个虚拟代言人拍系列广告?个人想为自己打造一个跨场景的数字分身?技术门槛正在被急剧拉平。
当然,好导演不止会调教演员。
可灵AI 3.0自己就内置了一个“智能分镜系统”。你输入一段剧本式的描述,AI能自动理解并调度景别与机位——什么时候该给特写,什么时候切到反打镜头,它心里有数。配合上最长15秒的生成能力,一段有起承转合、富有电影感的叙事片段,真的可以一键生成。
更贴心的是,它甚至解决了口型同步这个世界难题。支持中、英、日、韩、西五种语言及多种方言,确保角色说话时嘴唇动作、神态与音色完美匹配。视频里的招牌、字幕,也都能清晰可辨。
这不再是玩具。这是朝着“影视级直接交付”迈进的生产力工具。
别忘了,这次是All-in-One的全家桶更新。
同步升级的可灵图片3.0,分辨率直接拉到2K/4K,专为影视预演和高质量场景设定准备。它新增的“组图生成”功能,能用单张或多张图作为起点,批量产出一系列逻辑连贯的画面,像分镜头脚本一样,极大提升了前期构思的效率。
从一张高精度概念图,到一组连贯的分镜,再到一段由固定主角演绎的成片——一个属于创作者的、无缝衔接的AI影像闭环,已经清晰可见。
目前,模型已面向黑金会员开启内测,预计很快将全量上线。内测聚焦于超前体验,而全量开放,无疑将掀起新一轮的创作海啸。
电影叙事、品牌内容、个人表达……视频创作的所有边界都在松动。那个需要昂贵设备、专业团队和漫长周期的时代,正在被一行行文本提示词快速重构。
技术的突进,从来不只是让旧事情做得更快。而是让原本不敢想的人,开始第一次尝试。
导演的椅子,现在空出了一把。
所有领域都值得用AI重做一遍。本文作者承接各种AI智能体和AI全域营销自动化软件、工作流开发,了解加微信:qimugood(读者也可此微信一起交流)。
文章标题:可灵AI 3.0发布,让AI‘认人’了。一段3秒视频,就能生成主角一致的成片。
文章链接:https://qimuai.cn/?post=3186
本站文章均为原创,未经授权请勿用于任何商业用途